Transparent Prompting Flow
What are Tokens?
Tokens are the basic units that AI language models use to process and understand text. Think of them as the "building blocks" of language that the AI reads and generates.TODO
How it works:
When you send a message, the AI breaks it down into tokens before processing itTokens can be whole words, parts of words, or even individual charactersOn average, 1 token ≈ 4 characters or ¾ of a word in EnglishFor example: "Hello, how are you?" = approximately 6 tokens
Why tokens matter:
Cost: Most AI services charge based on tokens used (both input and output)Conversation length: AI models have a maximum token limit for each conversationResponse limits: The AI can only generate a certain number of tokens per response
Practical examples:
A short message (50 words) ≈ 65-70 tokensA medium paragraph (200 words) ≈ 265-280 tokensA long roleplay response (500 words) ≈ 665-700 tokens
3 Types of Tokens
When you chat with AI in ISEKAI ZERO, tokens work in three different ways:
1. Input Tokens
Your prompts and messages to the AICommands and instructions you giveExample: "I try to explain to the adventurers that I'm not a real demon."
2. Cache Tokens (Your Smart Memory)
Previous conversation history that gets savedCharacter details and backstoryWorld information and scene contextThese are stored so the AI does not have to re-read everything from scratch
3. Output Tokens
The story content the AI writes backCharacter dialogue and responsesScene descriptions and narrative
How Tokens Flow in a Conversation
Step 1: You Send Your Action
Your prompt becomes Input Tokens.
"I try to convince the guards I'm just a normal traveler."
Step 2: AI Processes Your Request
The AI reads your message along with relevant Cache Tokens (previous story context) to understand the situation.
Step 3: AI Responds
The AI generates a story continuation as Output Tokens.
The guard eyes you suspiciously. "Normal travelers don't have horns," he mutters, hand moving to his sword...
Step 4: Important Details Get Cached
The AI automatically saves key information from this exchange as Cache Tokens for future use. This makes your next interaction faster and cheaper because the AI doesn't need to reload the entire conversation history—it already remembers the important parts.
Why This Matters
Input + Output = Your direct costs (what you pay per message)Cache = Your savings (prevents expensive re-processing)Longer conversations use more cache but save you money overallEach response builds on cached memory, creating a seamless story
Why Do Costs Vary Between Messages?
You often notice that some messages cost more than others, even if they are similar in length.
Here's why:
The Cache System Works on "Best Effort"
The AI tries to cache (save) your conversation history to reduce costs, but it can only reuse what is still valid. The cache system does its best effort with the current context.
Important: Cached tokens are significantly cheaper than regular input tokens but the exact discount varies depending on the situation.
How Cache Saves You Money
Example:
Your conversation needs10,000 input tokensto processThe AI successfully caches8,000 tokensfrom previous turnsResult:Those 8,000 cached tokens cost a fraction of their original price (often around 10% or less, but this varies)
The savings:
2,000 regular input tokens = Full price8,000 cached tokens = Much cheaper (discount varies)Total = Significantly less than paying full price for all 10,000 tokens!
Why Cache Effectiveness Varies
Cache works GREAT when:
✅ You are actively chatting (within 5 minutes of last message)✅ Your conversation history stays unchanged✅ Character details remain the same✅ No edits to previous messages
Cache is LOST or REDUCED when:
❌ 5+ minutes pass without interaction (cache expires)❌ You edit a previous message (invalidates cache from that point)❌ You modify character details (changes the context)❌ Previous conversation turns are altered
The 5-Minute Rule
Your cache expires after 5 minutes of inactivity.
If you reply within 5 minutes → Cache is still active → Lower costsIf you wait longer than 5 minutes → Cache expires → Full input token costs
This is why costs can spike after breaks. The AI has to reload everything at full price.
Bottom Line
The cache system tries to save you money, but it needs:
Continuous interaction (replies within 5 minutes)Unedited conversation historyUnchanged character information
Pro Tips for Lower Costs:
Reply within 5 minutes to keep cache activeAvoid editing previous messages when possiblePlan your character details before startingTake longer breaks between sessions instead of many small breaks
The system always does its "best effort" to cache what it can, these factors just determine how much it is able to save.
How Tokens are Calculated?
Example:
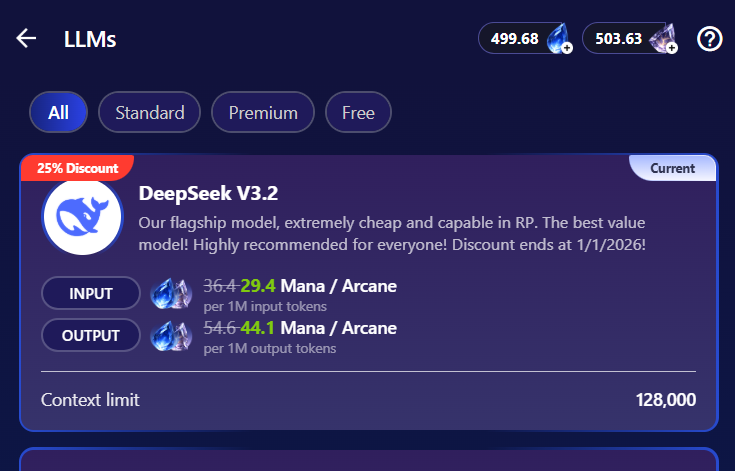
DeepSeek V3.2, it costs
29.4 Mana / Arcane per 1M input tokens44.1 Mana / Arcane per 1M output tokens
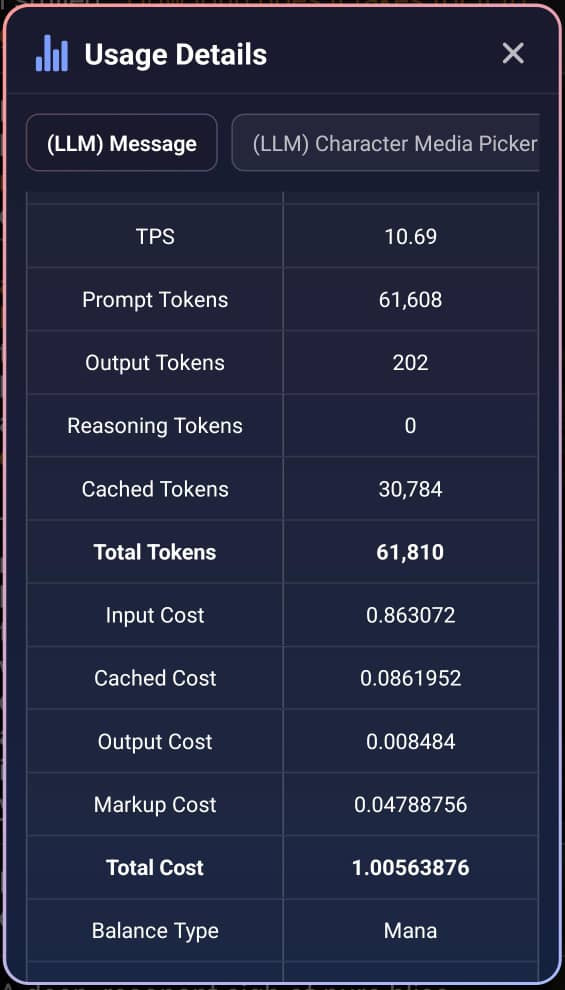
Total Tokens: 61,810
Prompt Tokens: 61,608Cached: 30,784Fresh Input: 30,824 (61,608 - 30,784)
Output Tokens: 202
Cost Calculations
Fresh Input Tokens Cost = (30,824 / 1,000,000)× 29.4 = 0.9062256 ManaCached Tokens Cost =(30,784 / 1,000,000)× 2.94 = 0.09050496 ManaOutput Tokens Cost =(202 / 1,000,000)× 44.1 = 0.0089082 Mana
Total Cost: 1.00563876 Mana
If ALL 61,608 prompt tokens were charged at FULL price,
Input Tokens Cost = (61,608 / 1,000,000)× 29.4 = 1.8112752 ManaOutput Tokens Cost =(202 / 1,000,000)× 44.1 = 0.0089082 Mana
Without Cache: 1.8201834 Mana
Total Tokens Saved: 0.8147958 Mana (44.75% cheaper)