トークンとは?
「なぜメッセージごとにコストが異なるのか?」というご質問を多くいただいています。透明性を重視しているため、仕組みを隠すのではなく、LLMの料金構造について簡単にご説明します。
当社では、AIプロバイダーが設定する料金に30%のサービス料を加算しています。そのうち25%は、クリエイターへの利益還元に充てられます。詳しくは「透明な価格設定」をご覧ください。
トークンとは、AIが文章を処理・理解するための基本単位です。AIが読み取り、生成する言語の「構成要素」とも言えます。
仕組みについて:
-
メッセージを送信すると、AIは処理前にそれをトークンに分解します。
-
トークンは単語全体、単語の一部、または1文字の場合もあります。
-
英語では平均して、1トークンは約4文字、または1単語の約4分の3に相当します。
-
例:「Hello, how are you?」≈ 約6トークン
トークンが重要な理由:
-
コスト: 多くのAIサービスでは、使用されたトークン数(入力・出力の両方)に基づいて料金が計算されます。
-
コンテキスト制限: AIモデルには、1つの会話の中で処理できるトークン数に上限があります。
-
レスポンスの制限: AIが1回のレスポンスで生成できるトークン数にも上限があります。
実際の目安:
-
短いメッセージ(約50語)≈ 65〜70トークン
-
中程度の段落(約200語)≈ 265〜280トークン
-
長めのロールプレイのレスポンス(約500語)≈ 665〜700トークン
3種類のトークン
ISEKAI ZEROでAIとチャットする際、トークンは3つの形で使われます。
1. 入力トークン(Input Tokens)
-
AIに送信するプロンプトやメッセージ。
-
入力するコマンドや指示。
-
例:「冒険者たちに、自分は本物の悪魔ではないと説明しようとする。」
2. キャッシュトークン(Cache Tokens)―スマートメモリシステム
-
保存された過去の会話履歴。
-
キャラクターの詳細な説明や設定・背景情報。
-
世界観に関する情報や、その時点のシーンの状況。
-
これらを保存しておくことで、AIは毎回すべての状況を最初から読み直す必要がなくなります。
3. 出力トークン(Output Tokens)
-
AIが返答として生成するストーリーの内容。
-
キャラクターのセリフやレスポンス。
-
シーンの描写やナレーション。
会話におけるトークンの流れ
ステップ1:アクションを送信する
送信したプロンプトは、入力トークンとして処理されます。
例:「ただの旅人だと衛兵たちを説得しようとする。」
ステップ2:AIがリクエストを処理する
AIはメッセージを読み取り、関連するキャッシュトークン(過去のストーリーの状況)とあわせて、現在の状況を理解します。
ステップ3:AIが返答する
AIはストーリーの続きを出力トークンとして生成します。
例:衛兵はじっとこちらを見つめる。「普通の旅人に角は生えていない」と低くつぶやきながら、剣に手をかけた……
ステップ4:重要な情報がキャッシュされる
AIはこのやり取りから重要な情報を自動的にキャッシュトークンとして保存し、次回以降に活用します。これにより、次のやり取りがより速く、より安くなります。会話履歴全体を再読み込みする必要がなく、重要な情報はすでに記憶されているためです。
なぜこれが重要なのか
-
入力+出力 = 直接コスト(1メッセージごとに発生する費用)
-
キャッシュ = コスト削減(同じ情報の再処理による高コストを防ぐ)
-
会話が長くなるほどキャッシュ使用量は増えますが、全体的なコストは抑えられます。
-
各レスポンスはキャッシュされたメモリをもとに生成されるため、ストーリーが一貫して続きます。
メッセージによってコストが変わる理由
長さが似ているメッセージでも、コストが異なる場合があります。その理由を説明します。
キャッシュシステムはベストエフォート方式で動作する
AIは、会話履歴をキャッシュ(保存)することでコスト削減を試みます。
ただし、再利用できるのは有効なキャッシュのみです。キャッシュシステムは、現在のコンテキストに応じてベストエフォート方式で機能します。また、すべてのLLMモデルがキャッシュに対応しているわけではありません。
重要: キャッシュされたトークンは、通常の入力トークンに比べて大幅に安く処理されることがありますが、割引率は状況やモデルによって異なります。
キャッシュによるコスト削減の例
会話の処理に 10,000入力トークン が必要だとします。
そのうち、AIが過去のやり取りから 8,000トークン をキャッシュとして再利用できた場合、結果としてその 8,000キャッシュトークン は、通常価格のごく一部(多くの場合は10%未満ですが、変動する場合があります)で処理されます。
節約の内訳:
-
2,000の通常入力トークン = 通常料金
-
8,000のキャッシュトークン = 大幅割引(割引率は変動)
-
合計:10,000トークンすべてを通常料金で処理する場合と比べて、大幅に安くなります。
キャッシュの有効性が変わる理由
キャッシュが有効に機能する場合:
✅ アクティブにチャットしている(最後のメッセージから5分以内)
✅ 会話履歴が変更されていない。
✅ キャラクターの詳細が変更されていない。
✅ 過去のメッセージを編集していない。
キャッシュが失われる、または効果が下がる場合:
❌ 5分以上操作がない(キャッシュが期限切れになる)
❌ 過去のメッセージを編集した(その時点以降のキャッシュが無効になる)
❌ キャラクターの詳細を変更した(コンテキストが変わる)
❌ 過去の会話内容が変更された
❌ AIプロバイダー側でサービス障害が発生している
5分ルール
キャッシュは操作がない状態が5分続くと期限切れになります。
-
5分以内に返信した場合 → キャッシュが有効 → 低コスト
-
5分以上空いた場合 → キャッシュが期限切れ → 入力トークンが通常料金で計算される
休憩後にコストが上がることがあるのはこのためです。AIはすべての情報を通常料金で再読み込みする必要があります。
まとめ
キャッシュシステムはコスト削減を目的としていますが、以下の条件が必要です:
-
継続的なやり取り(5分以内の返信)
-
会話履歴を編集しないこと
-
キャラクター情報を変更しないこと
コストを抑えるためのヒント:
-
キャッシュを維持するために5分以内に返信する
-
できるだけ過去のメッセージを編集しない
-
チャットを始める前にキャラクターの詳細を決めておく
-
細かい休憩を何度も取るより、セッション間にまとめて長い休憩を取る
キャッシュは「ベストエフォート方式」であり、保証されるものではありません
キャッシュはベストエフォート方式で動作しており、常に成功が保証される仕組みではありません。制御できないさまざまな要因によって、キャッシュが機能しない場合があります。
キャッシュが予期せず機能しなくなる原因:
-
サーバー側の要因 — アクセス集中、メンテナンス、システム更新などにより、AIプロバイダー側でキャッシュがクリアされる場合があります。
-
モデルのルーティング — リクエストが、キャッシュデータを保持していない別のサーバーインスタンスで処理される場合があります。
-
インフラの変更 — バックエンドの更新や負荷分散によって、既存のキャッシュが無効になることがあります。
-
トークン制限 — 会話が長くなりすぎると、古いキャッシュ内容が削除される場合があります。
-
プロバイダーのポリシー — キャッシュの扱いはAIプロバイダーによって異なり、事前の告知なく変更されることがあります。
注意点:
すべての条件を満たしていても(5分以内の返信、メッセージの編集なしなど)、キャッシュミスによってコストが高くなる場合があります。これは異常ではなく、分散型AIシステムの仕組みによる通常の動作です。
要点:キャッシュは、全体として見るとコスト削減に役立ちますが、個々のメッセージに必ず適用されるわけではありません。そのため、「通常は適用される可能性がある割引」として捉え、常に保証されるものではないとご理解ください。
トークンコストの計算方法
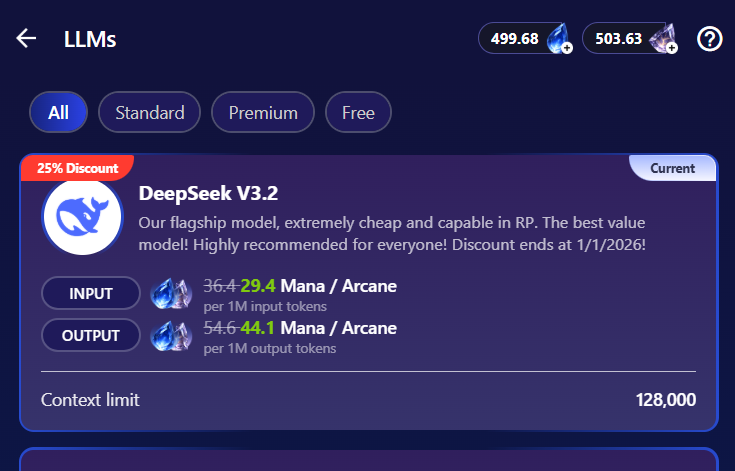
例:DeepSeek V3.2 の場合
|
種別 |
単価 |
|
入力トークン |
100万トークンあたり 29.4マナ/アルケイン |
|
出力トークン |
100万トークンあたり 44.1マナ/アルケイン |
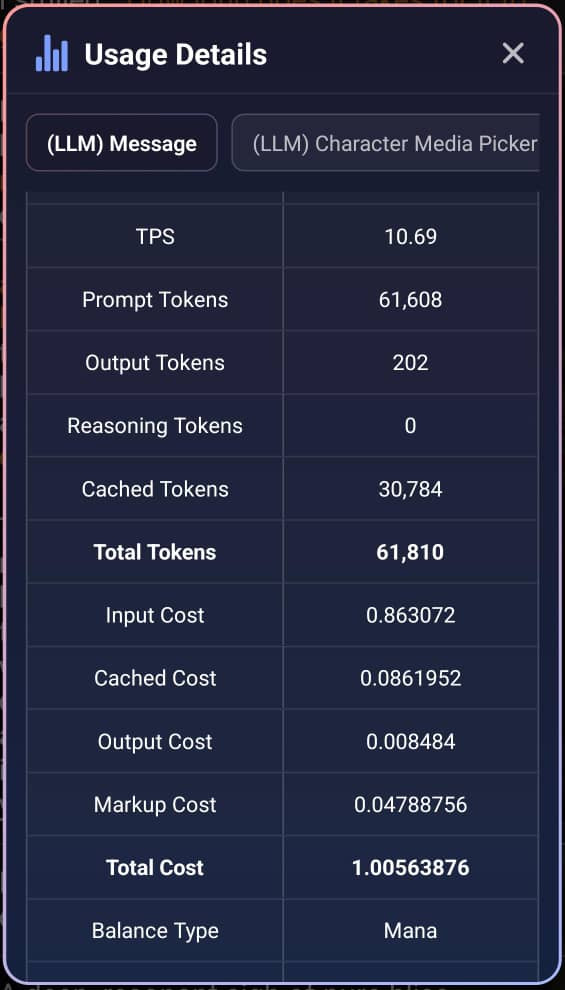
トークン内訳:合計 61,810トークン
-
プロンプトトークン:61,608
-
キャッシュ済み:30,784
-
新規入力:30,824(61,608 − 30,784)
-
出力トークン:202
コスト計算:
-
新規入力トークンのコスト = (30,824 ÷ 1,000,000) × 29.4 = 0.9062256 マナ
-
キャッシュトークンのコスト = (30,784 ÷ 1,000,000) × 2.94 = 0.09050496 マナ
-
出力トークンのコスト = (202 ÷ 1,000,000) × 44.1 = 0.0089082 マナ
-
合計:1.00563876 マナ
もし61,608プロンプトトークンすべてが通常料金で請求された場合:
-
入力トークンのコスト = (61,608 ÷ 1,000,000) × 29.4 = 1.8112752 マナ
-
出力トークンのコスト = (202 ÷ 1,000,000) × 44.1 = 0.0089082 マナ
-
キャッシュなしの場合:1.8201834 マナ
節約されたトークンコスト:0.8147958 マナ(44.75%削減)
トークンの種類まとめ
|
項目 |
入力トークン |
キャッシュ読み取りトークン |
出力トークン |
|
説明 |
送信する内容 |
AIが記憶している内容 |
AIが生成する内容 |
|
コスト |
中程度 |
非常に安い |
最も高い |
|
理由 |
AIがテキストを読み取る |
AIが保存済みの内容を再利用する |
AIが新しい内容を生成する |